RL Applications
https://www.youtube.com/watch?v=ITfBKjBH46E
Agent-Environment Interface
- Agent: learner and decision maker.
- Environment: the thing agent interacts with, comprising everything outside the agent.
- Action: how agent interacts with the environment.
- In engineers’ terms, they are called controller, controlled system (or plant), and control signal.
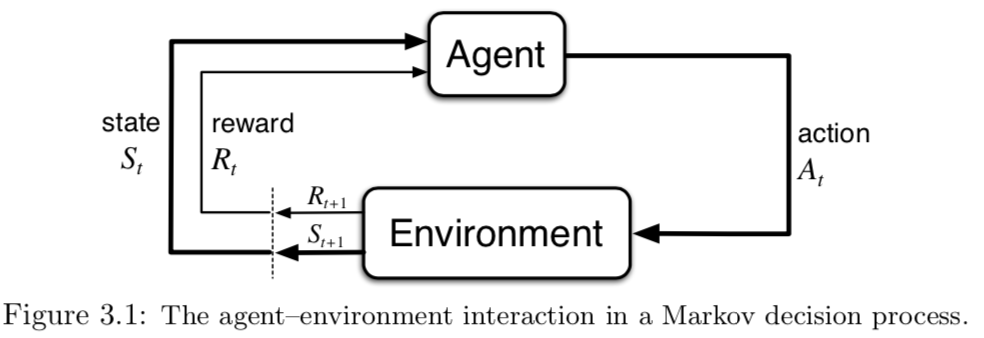
Agent-Environment Interface
- At each step \(t\) the agent
- Executes action \(A_t\)
- Receives state \(S_t\)
- Receives scalar reward \(R_t\)
- The environment
- Receives action \(A_t\)
- Emits state \(S_{t+1}\)
- Emits scalar reward \(R_{t+1}\)
Maze Example
- States: Agent's location
- Actions: N, E, S, W, stay
- Reward: -1 per time-step
- Termination: Reach goal

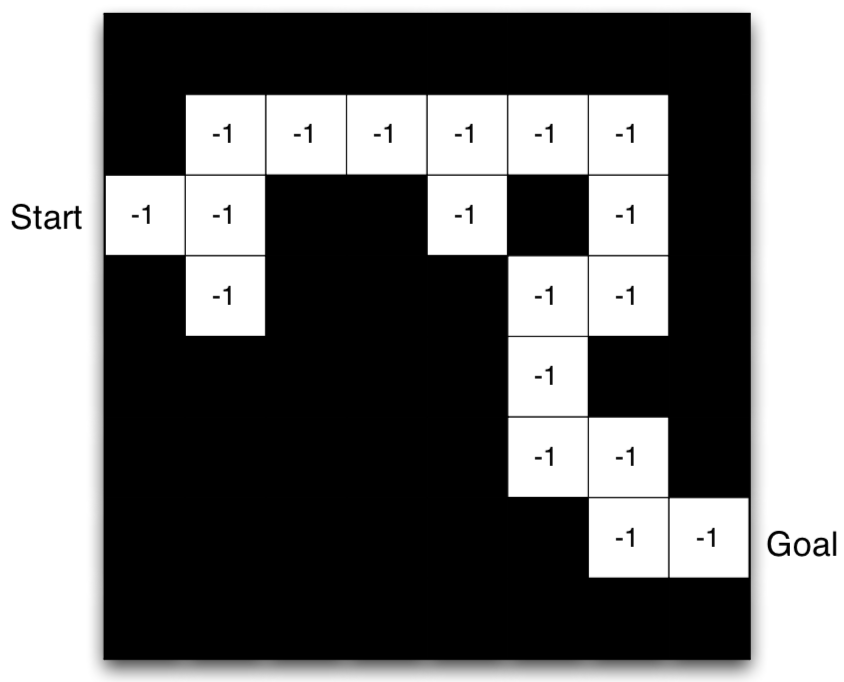
Maze Example: Model
- Agent may have an internal model of the environment
- Dynamics: how actions change the state
- Rewards: how much reward from each state
- In the right figure:
- Grid layout represents transition model $\mc{P}_{s,s'}^a$
- Numbers represent immediate reward $\mc{R}_s^a$ from each state $s$ (same for all $a$)
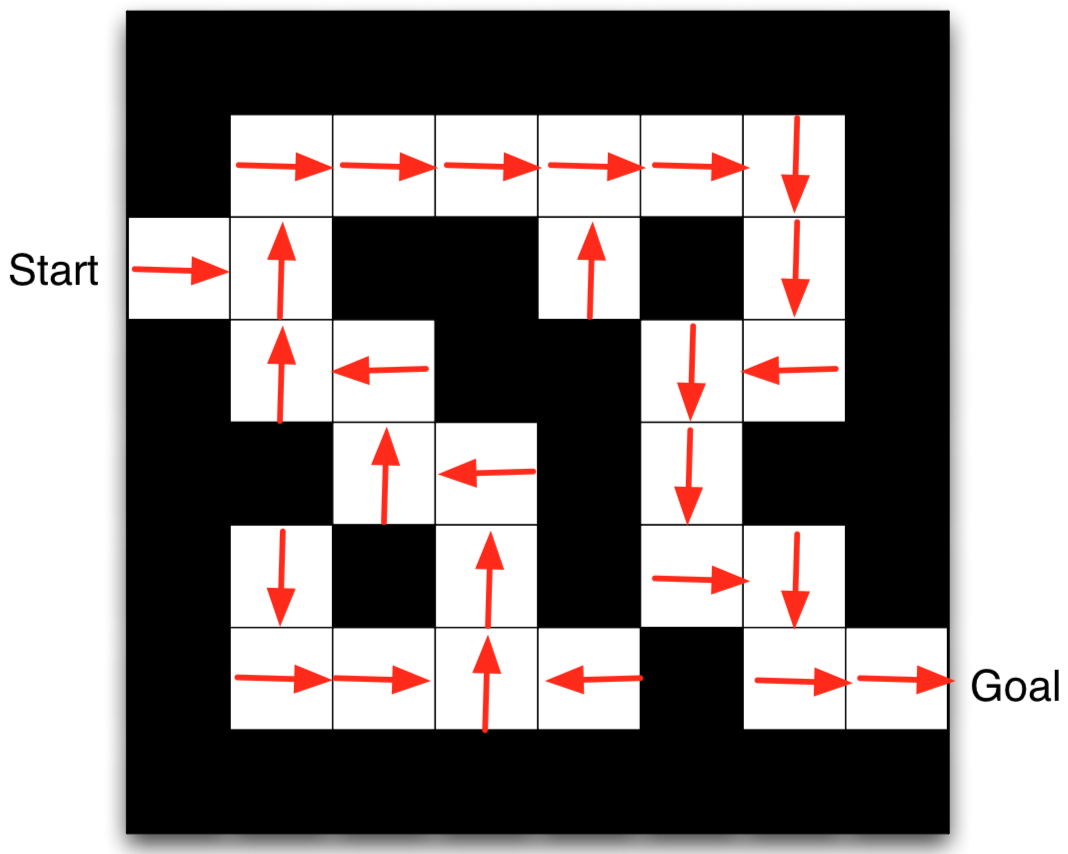
Maze Example: Policy
- Arrows represent policy $\pi(s)$ for each state s
- This is the optimal policy for this Maze MDP
Maze Example: Value Function
- Numbers represent value $V_\pi(s)$ of each state $s$
- This is the value function corresponds to the optimal policy we showed previously

